Почему у самообучающегося искусственного интеллекта есть проблемы с реальным миром. Самообучающийся искусственный интеллект
Ученые из США создали самообучающийся ИИ, способный сломать любую капчу
21:0226.10.2017
(обновлено: 21:03 26.10.2017)
52171113
МОСКВА, 26 окт – РИА Новости. Американские инженеры создали новую систему искусственного интеллекта, способную к самостоятельному обучению, и приспособили ее для взлома текстовых капч, используемых веб-мастерами для защиты сайтов от ботов. Инструкции по созданию этого ИИ были опубликованы в журнале Science.
"Умение учиться, используя лишь небольшой набор примеров, и умение находить общие черты в самых разных ситуациях являются отличительными чертами человека, которые пока оставались недоступными машинам. Используя опыт системной нейрофизиологии, мы создали новую модель компьютерного зрения, которая распознает капчи лучше, чем это делают глубинные нейросети, и при этом работает в 300 раз более эффективно", — заявил Дилип Джордж (Dileep George), один из основателей IT-стартапа Vicarious AI.
Главным недостатком всех существующих сегодня нейросетей и систем искусственного интеллекта является то, что они не могут самостоятельно осваивать новые навыки и умения. Инженерам в буквальном смысле приходится обучать их тому, что они должны делать, используя огромные архивы данных, вручную обработанные человеком, или при непосредственном участии людей, показывающих машине, как нужно правильно решать задачи.
Это свойство резко ограничивает применимость систем ИИ в реальной жизни, так как подобные программы в принципе не способны учиться самостоятельно, наблюдая за действиями людей или других машин, и не могут подхватывать новые навыки и знания "на лету", как человек. Кроме того, способности таких систем ИИ, по сути, ограничиваются тем, как хорошо их обучили люди, что в принципе не позволяет им выйти на "сверхчеловеческий" уровень работы.
Джордж, нейрофизиолог по образованию, и IT-предприниматель Скотт Финикс (Scott Phoenix) шесть лет назад основали проект Vicarious, нацеленный на ликвидацию этого недостатка ИИ. В 2013 году они представили первую свою разработку – так называемую "рекурсивную кортикальную сеть"(RCN), особый подвид нейросети, имитировавший то, как работает визуальная кора мозга.
Система ИИ, построенная на базе RCN, как тогда заявляли Джордж и Финикс, смогла успешно взломать примерно 90% текстовых капч, применявшихся в то время для защиты сайтов. Почти все специалисты в этой области не поверили основателям Vicarious, заявив, что они могли подтасовать данные или построить и натренировать нейросеть специально для подбора ответов на такие головоломки.
На этот раз Финикс и Джордж представили итоги своей работы в престижном научном журнале Science, создав новую версию RCN, которая может научиться распознавать буквы и цифры произвольной формы, нарисованные на капчах, самостоятельно изучив всего 260 примеров подобных головоломок.
Ключевой особенностью этой системы, как объясняет Джордж, является то, что делит воспринимаемую ей картинку на два типа объектов – поверхности и контуры. За их распознавание отвечает две раздельных нейросети, организованных примерно таким же образом, как слои нейронов в визуальной коре мозга, а результаты их работы объединяет еще одна сеть, состоящая из двух слоев.
Подобный подход, как отмечают ученые, позволяет разбивать буквы, цифры и другие объекты на наборы отдельных элементов, часть из которых является общей для многих символов, что ускоряет процесс самообучения сети и повышает точность распознавания даже самых стилизованных и неоднозначных надписей.
Как показали первые опыты с этой системой ИИ, всего трех сотен раундов пробных тестах на простых капчах хватило для того, чтобы RCN научился взламывать антиспам-системы Paypal, Yahoo, reCAPTCHA и многих других популярных систем "бот-проверок" с 66% вероятностью. Что интересно, шансы на успех не зависели от расстояния между буквами и их формы, двух главных "врагов" обычных нейросетей.
Подобный показатель, как отмечают ученые, в разы превышает точность работы всех существующих систем машинного обучения, предназначенных для подобных целей, и его можно существенно повысить, если позволить ИИ тренироваться дольше, и использовать те шрифты, которые применяются создателями подобных головоломок.
Искусственный интеллект впервые победил лучших игроков в покерria.ru
учёные сообщают об успехах в самообучении искусственного интеллекта / Хабр
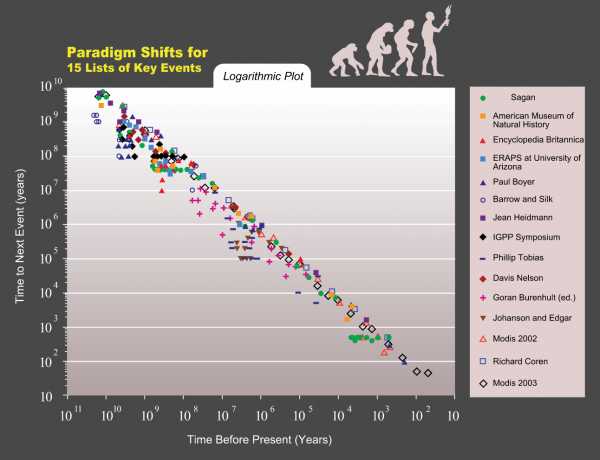 По Курцвейлу, логарифмическая шкала смены парадигм для ключевых исторических событий проявляет экспоненциальную тенденцию
По Курцвейлу, логарифмическая шкала смены парадигм для ключевых исторических событий проявляет экспоненциальную тенденциюКлючевой элемент для возникновения технологической сингулярности — запуск неконтролируемого цикла самосовершенствования ИИ, где каждое новое более умное поколение ИИ будет появляться быстрее предыдущего. Согласно теории сингулярности по Вернору Винджу, в результате взрывного развития интеллекта в цикле экспоненциального самосовершенствования появится сверхинтеллект, который намного превзойдёт возможности человеческого разума и по сути будет непонятен для него. Называются разные примерные даты наступления сингулярности, исходя из экстраполяции технологического прогресса. Рей Курцвейл считает, что это произойдёт примерно в 2045 году (хотя он не считает обязательным экспоненциальное самосовершенствование ИИ), а среднее медианное значение по опросу экспертов по сильному ИИ — 2040 год.
Вполне возможно, что сингулярность наступит раньше прогнозируемого. Инженеры из компании Google и разработчики систем ИИ из других компаний сообщают об успехах, которых удалось добиться в ключевом направлении — создании систем ИИ, предназначенных для проектирования других систем ИИ. В одном из экспериментов исследователи ИИ из подразделения Google Brain разработали программу, которая проектировала нейронную архитектуру нейросети таким образом, чтобы та показывала максимально высокие результаты в распознавании речи. Спроектированная программным методом система показала лучший результат, чем созданные человеком нейросети.
Издание MIT Technology Review рапортует, что в последние месяцы об успехах по созданию систем ИИ для проектирования других систем ИИ сообщили несколько исследовательских коллективов, в том числе из некоммерческой организации OpenAI (финансируется Илоном Маском), Массачусетского технологического института, Калифорнийского университета в Беркли, а также ещё одного подразделения по искусственному интеллекту в компании Google — DeepMind. Очевидно, это направление научных исследований считается одним из самых перспективных, многие хотят преуспеть в нём.
По мнению MIT Technology Review, такие разработки в первую очередь преследуют экономическую цель. Создание программы для проектироания приложений ИИ значительно ускорит применение подобных технологий в разных сферах экономики. Сейчас многие компании не могут себе позволить внедрить систему ИИ, потому что в штате нет специалиста с такой компетенцией. Банально, эксперты по ИИ в большом дефиците. А ведь нейросети можно применять практически в огромном количестве приложений: в автомобильной промышленности, в банковской сфере, в телекоммуникациях, в системах безопасности и видеонаблюдения, в самых разных потребительских продуктах для распознавания речи и жестов, машинного зрения и т.д.
Разработка систем ИИ программными методами позволит заменить часть этих дефицитных программистов.
Важно ещё и то, что ИИ разрабатывает нейросети более эффективные, чем человек, поэтому внедрение таких программ имеет смысл даже там, где раньше работали живые разработчики.
На эту тему рассуждал недавно Джефф Дин (Jeff Dean), руководитель исследовательской группы Google Brain. В своём выступлении на конференции AI Frontiers в Санта-Кларе (Калифорния) он предположил, что часть таких программистов можно заменить программным обеспечением, потому что в данный момент компаниям приходится платить очень высокие деньги и зарплату этим специалистам, которых крайне не хватает.
Например, в научной статье "Learning to reinforcement learn" от DeepMind описан набор экспериментов для самообучения ИИ, который исследователи называют «глубокое мета-обучение с подкреплением» (deep meta-reinforcement learning). Суть заключается в том, чтобы использовать стандартное обучение с подкреплением нейросети с обратной связью таким образом, чтобы эта рекуррентная нейросеть разработала собственную свободную от внешних шаблонов процедуру обучения с подкреплением для другой рекуррентной нейросети.
Эксперименты показали, что нейросеть второго порядка, созданная усилиями первой нейросети, в некоторых случаях демонстрирует эффективность и качества, которыми не обладает нейросеть первого порядка.
Всего в научной работе DeepMind описано семь таких экспериментов. Как обычно, они проводят их в пространстве компьютерных игр. По мнению исследователей, подобные агенты ИИ, созданные с помощью других программ ИИ, способны быстрее адаптироваться к новым задачам, используя полученные ранее знания на схожих задачах. Эксперименты показали также, что результат обучения ИИ второго порядка можно считать непредсказуемым: его архитектура не зависит от архитектуры ИИ первого порядка и может сильно отличаться от неё. В частности, ИИ второго порядка способен использовать особенности среды, о которых не знали или не которые не учитывались самими разработчиками.
Специалисты DeepMind считают, что их эксперименты с глубоким мета-обучением с подкреплением имеют значение и в изучении человеческого мозга, в частности, они «обеспечивают интегративный фреймворк для понимания соответствующих ролей допамина и префронтальной коры головного мозга в биологических процессах обучения с подкреплением».
Идея самообучения ИИ выдвигалась и раньше, но до сих пор учёным не удавалось продемонстрировать настолько впечатляющих результатов. Например, один из пионеров в этой области, профессор Йошуа Бенжио (Yoshua Bengio), говорит, что такие эксперименты требуют слишком больших вычислительных мощностей, так что до последнего времени они не имели практического смысла. Например, в опытах Google Brain для работы программного обеспечения, которое проектирует систему ИИ для машинного зрения, использовалось 800 высокопроизводительных графических процессоров.
Исследователи из Массачусетского технологического института планируют опубликовать исходный код программы, которую использовали в своих экспериментах. Возможно, со временем использование таких инструментов будет иметь экономический смысл и оно снизит нагрузку на специалистов, которые разрабатывают модели для обработки данных. Высококвалифицированные программисты смогут отвлечься от кодинга и сконцентрироваться на идеях более высокого порядка.
habr.com
Программа искусственного интеллекта ЭЛИС
Программа искусственного интеллекта ЭЛИС.
Система искусственного интеллекта ЭЛИС представляет собой программное обеспечение, способное разговаривать как человек на простом языке, управлять устройствами, а также обучаться. С помощью данной программы можно общаться с компьютером, а также взаимодействовать с физическим миром. Программа также использует возможность подключения Ардуино, чтобы создавать системы умного дома, автоматики и т.д.
Скачать программу искусственного интеллекта ЭЛИС
Описание
Модули
Описание:
Программа искусственного интеллекта ЭЛИС — Электронно Логически Интеллектуальная Система. Система искусственного интеллекта ЭЛИС представляет собой программу. Это программное обеспечение, способное разговаривать как человек на простом языке, управлять устройствами, а также обучаться. Данная система не является ассистентом, так как упор идёт на разработку человекоподобной системы, которая сможет обучаться как ребёнок и вести осознанный диалог.
С помощью данной программы можно общаться с компьютером, а также взаимодействовать с физическим миром. Программа также использует возможность подключения Ардуино, чтобы создавать системы умного дома, автоматики и т.д.
Система искусственного интеллекта ЭЛИС построена по модульному принципу. Система универсальна и её функционал наращивается с помощью модулей. Модули могут быть различные, от простых, до сложных.
Программа искусственного интеллекта ЭЛИС самостоятельно ведет диалог с человеком.
Она может самостоятельно начать диалог, может делать это несколько раз, что уже отличает её от голосовых асистентов, которые работают по структуре вопрос — ответ. Программа искусственного интеллекта ЭЛИС самостоятельно принимает решение после того, что скажет человек, и если не знает, её можно обучить.
При поддержке диалога с пользователем система сама обучается. Система способна запоминать несколько ответов на один или множество вопросов и иметь несколько вопросов на один или множество ответов.
Программа искусственного интеллекта ЭЛИС полностью совместима с платформой Ардуино, поэтому можно управлять любыми устройствами. Можно попросить у системы включить свет, система спросит, где именно включить, но можно попросить включить свет сразу в определённом месте, тогда она не будет переспрашивать.
Программа искусственного интеллекта ЭЛИС также способна запускать сторонние приложения и т.д.
Модули:
В настоящий момент программа искусственного интеллекта ЭЛИС включает следующие модули:
— модуль «Знания» — модуль поиска информации по WIKIPEDIA. Система знает любое устройство, предмет и так далее, Спросите например, что такое велосипед или что такое яблоко и система расскажет, что это такое,
— модуль «Новости». Свежие новости на интересы пользователя. Просто спросите, какие новости или расскажи новости, система расскажет и спросит, надо ли рассказать ещё, ответив да, она расскажет ещё,
— модуль «Погода». Погода на сегодня и на завтра по моему городу. Можно узнать температуру, влажность, скорость ветра, будет ли дождь или мороз. Можно спросить, брать ли зонтик сегодня или можно ли одеть сегодня шорты,
— модуль «Калькулятор». С помощью данного модуля, система умеет складывать, вычитать, умножать и делить предметы и т.д. Например спросив, сколько будет два яблока плюс два яблока, система ответит четыре яблока. Модуль в разработке,
— модуль «Будильник». Модуль позволяет устанавливать любое количество будильников. Установив будильник, система Вас разбудит. Просто надо сказать, разбуди меня в 7 утра. Модуль в разработке,
— модуль «Корректировка ответов». Правильная расстановка знаний в базе,
— модуль «Праздники, именины, события». Данный модуль позволяет узнать, кому сегодня день имени или какой сегодня праздник,
— модуль «Тосты». Модуль позволяет системе говорить различные тосты. Надо попросить, скажи тост,
— модуль «Анекдоты». Система знает тысячи анекдотов. Просто попросите её рассказать анекдот, так-же можно попросить рассказать анекдот для взрослых,
— модуль «Стихи». Данный модуль превращает систему в поэта. Просто попросите рассказать стих, так-же можно попросить рассказать стих для взрослых,
— модуль «Афоризмы». Система знает тысячи афоризмов. Просто попросите её сказать афоризм, так-же можно попросить сказать афоризм для взрослых,
— модуль «Управление освещением». С помощью данного модуля, система умеет управлять освещением квартиры или дома. Для этого надо подключить Arduino и Ethernet Shield,
— модуль «Угадывание цифры». Система пытается угадать загаданную цифру. Называет предполагаемую цифру, после надо ей сказать, больше или меньше. Модуль в разработке,
— модуль «Пользователь». Модуль позволяет изменять данные пользователя, имя, город и т.д. Например чтобы поменять имя, надо сказать, запомни меня зовут Олег и она запомнит,
— модуль «Диалог». Анализ диалога. Модуль, который обрабатывает диалог за сутки, анализируя пользователя, обучаясь и т.д.
Примечание: описание технологии на примере программы искусственного интеллекта ЭЛИС.
РЕКОМЕНДАЦИИ ПО ИСПОЛЬЗОВАНИЮ ТЕХНОЛОГИЙ
ЗВОНИТЕ: +7-908-918-03-57
либо воспользуйтесь поиском аналогов технологий:
ПОИСК АНАЛОГОВ ТЕХНОЛОГИЙ
или пиши нам здесь...карта сайта
Войти Регистрация
Виктор ПотехинПоступил вопрос по выращиванию сапфиров касательно технологии и оборудования. Дан ответ.
2018-05-16 20:23:28Виктор ПотехинПоступил вопрос касательно мотор-колеса Дуюнова и мотор-колеса Шкондина, что лучше. Дан ответ.
2018-05-16 20:30:50Виктор ПотехинПоступил вопрос об организациях, которые осуществляют очистку металла от ржавчины. Дан ответ: оставляйте свои заявки внизу в комментариях. Производители сами найдут вас и свяжутся.
2018-05-17 10:35:28Виктор ПотехинПоступил вопрос касательно санации трубопровода. Дан ответ. В частности указана более инновационная технология.
2018-05-17 18:10:26Виктор ПотехинПоступил вопрос касательно сотрудничества, а именно: определения направлений развития предприятия и составления планов будущего развития. В настоящее время ведутся переговоры. Будет проанализирована исходная информация, совместно выберем инновационные направления и составим планы.
2018-05-18 10:34:05Виктор ПотехинПоступил вопрос касательно электрохимических станков. Дан ответ.
2018-05-18 10:35:57Виктор ПотехинПоступил вопрос относительно пиролизных установок для сжигания ТБО. Дан ответ. В частности, разъяснено, что существуют разные пиролизные установки: для сжигания 1-4 класса опасности и остальные. Соответственно разные технологии и цены.
2018-05-18 11:06:55Виктор ПотехинК нам поступают много заявок на покупку различных товаров. Мы их не продаем и не производим. Но мы поддерживаем отношения с производителями и можем порекомендовать, посоветовать.
2018-05-18 11:08:11Виктор ПотехинПоступил вопрос по гидропонному зеленому корму. Дан ответ: мы не продаем его. Предложено оставить заявку в комментариях для того, чтобы его производители выполнили данную заявку.
2018-05-18 17:44:35Виктор ПотехинПоступает очень много вопросов по технологиям. Просьба задавать эти вопросы внизу в комментариях к записям.
2018-05-23 07:24:36Andrey-245Не совсем понятно. Эту батарейку можно вообще не заряжать что ли? Сколько вольт она выдает? И где ее купить? И можно ли такие соединить последовательно-параллельно, собрав нормальный аккумулятор, например, для электромобиля?
2018-08-23 10:09:48Виктор ПотехинАндрей, какую батарейку?
2018-08-24 08:33:25SergeyShefДобрый день! Интересна вышеописанная установка. Как можно её заказать ? Какие условия сотрудничества у автора?
2018-08-27 17:07:42Виктор ПотехинСергей, кидайте сюда ссылку на установку. Или пишите мне vnp1@ya.ru
2018-08-27 18:52:14SergeyShefЯ у Вас спрашивал, как и где её можно купить?
2018-08-27 21:07:41SergeyShefКто изготовил тот образец, который у Вас на фото и могут ли изготавливать на заказ?
2018-08-27 21:10:05Виктор Потехинне могу понять, что за установка. скиньте сюда ссылку
2018-08-27 23:15:16Виктор Потехинне обладаем такой информацией
2018-08-28 21:45:17npc-sesДобрый день! SergeyShef изделие подобное тому, что изображено в заголовке, да и в принципе любое изделие по технологии LTCC можно изготовить на нашем производстве АО "НПЦ "СпецЭлектронСистемы". Находимся в г. Москва. Можете написать мне на электронную почту vag_av@npc-ses.ru
2018-08-29 18:41:34npc-sesНа нашем производстве имеется пожалуй самый полный комплект оборудования в России, который позволяет производить 3D микросборки, в том числе по технологии LTCC, в замкнутом цикле, начиная от входного контроля материалов, всех промежуточных производственных процессов...
2018-08-29 18:47:20DjahanКРИОГЕЛЬ ДЛЯ РОСТА И РАЗВИТИЯ РАСТЕНИЙ В НЕБЛАГОПРИЯТНЫХ УСЛОВИЯХ. кто производит, как найти, чтобы купить?
2018-08-30 23:48:23Виктор Потехинкупить можно у производителя
2018-09-01 20:58:09Andrey-245Здравствуйте, Виктор. Я задавал вопрос (2018-08-23) имелось в виду про углеродную батарейку, которая служит более 100 лет.
2018-09-18 12:15:33Виктор Потехинвся информация, что есть по батарейке, написана в соответствующей статье.
2018-09-18 20:47:11Для публикации сообщений в чате необходимо авторизоваться
искусственный интеллект написать программу онлайн программа пишет программыискусственный интеллект программа для андроид для управления компьютером 2016 скачать с торрента программы голосовые скачать программу бесплатнолучшие программы искусственного интеллектановейшие программы с искусственным интеллектомпрограмма для создания искусственного интеллектапрограмма виртуальная девушка искусственный интеллектпрограмма голосовой искусственный интеллект для компьютера скачатьnai программа искусственного интеллекта для пк скачать торрент для компьютера с голосом 2016 скачатьпрограмма использующая искусственный интеллектпрограммы поиска в системах искусственного интеллектарабочая программа дисциплины теория искусственного интеллекта искусственный интеллектсамообучающиеся программы искусственного интеллектасистемы искусственного интеллекта рабочая программаскачать программу для создания искусственного интеллекта на компьютер 2017 для windows 7 с голосомскачать программу элис настоящий искусственный интеллектскачать самообучающуюся программу искусственного интеллекта на компьютер
Похожие записи
Количество просмотров с 26 марта 2018 г.: 6 470
comments powered by HyperCommentsxn--80aaafltebbc3auk2aepkhr3ewjpa.xn--p1ai
Почему у самообучающегося искусственного интеллекта есть проблемы с реальным миром
Новейшие системы ИИ начинают обучение, ничего не зная об игре, и вырастают до мирового уровня за несколько часов. Но исследователи с трудом справляются с применением таких систем за пределами игрового мира

До недавнего времени машины, способные посрамить людей-чемпионов, хотя бы имели уважение использовать человеческий опыт для обучения играм.
Чтобы выиграть у Гарри Каспарова в шахматы в 1997 году, инженеры IBM воспользовались столетиями шахматной мудрости при создании своего компьютера Deep Blue. В 2016 программа AlphaGo проекта Google DeepMind разгромила чемпиона Ли Седоля в древней настольной игре го, обработав миллионы игровых позиций, собранные с десятков тысяч партий между людьми.
Но сейчас исследователи ИИ переосмысливают то, как их боты должны впитывать человеческое знание. Текущую тенденцию можно описать как «да и бог с ним».
В прошлом октябре команда DeepMind опубликовала подробности новой системы игры в го, AlphaGo Zero, вообще не изучавшей игры людей. Она начала с правил игры и играла сама с собой. Первые ходы были совершенно случайными. После каждой игры она принимала новые знания о том, что привело к победе, а что – нет. После этих матчей AlphaGo Zero стравили с уже сверхчеловеческой версией AlphaGo, победившей Ли Седоля. Первая выиграла у второй со счётом 100:0. Ли Седоль, 18-кратный чемпион мира по го, матч против AlphaGo в 2016-м.
Ли Седоль, 18-кратный чемпион мира по го, матч против AlphaGo в 2016-м.
Команда продолжила изыскания и создала следующего гениального игрока в семействе AlphaGo, на этот раз названного просто AlphaZero. В работе, опубликованной на сайте arxiv.org в декабре, исследователи DeepMind раскрыли, как, снова начав с нуля, AlphaZero натренировалась и победила AlphaGo Zero – то есть, она победила бота, победившего бота, победившего лучшего игрока в го в мире. А когда ей дали правила для японских шахмат сёги, AlphaZero быстро обучилась и сумела обыграть лучшие их специально созданных алгоритмов для этой игры. Эксперты удивлялись агрессивному и незнакомому стилю игры программы. «Мне всегда было интересно, на что это было бы похоже, если бы превосходящие нас существа прилетели на Землю и показали бы нам, как они играют в шахматы, — говорил датский гроссмейстер Петер Хейне Нильсен в интервью ВВС. – Теперь я знаю».
В прошлом году мы видели и других ботов с иных миров, проявивших себя в настолько разных областях, как безлимитный покер и Dota 2 – популярной онлайн-игре, в которой фэнтезийные герои борются за контроль над иным миром.
Естественно, что амбиции компаний, инвестирующих деньги в подобные системы, простираются за пределы доминирования на игровых чемпионатах. Исследовательские команды вроде DeepMind надеются применять сходные методы к задачам реального мира – созданию сверхпроводников, работающих при комнатной температуре, или пониманию того, какое оригами свернёт белки в полезные для лекарств молекулы. И, конечно, многие практики надеются построить искусственный интеллект общего назначения – плохо определяемая, но пленительная цель дать машине возможность мыслить, как человек и гибко подходить к решению разных проблем.
Однако, несмотря на все вложения, пока неясно, насколько далеко смогут текущие технологии выйти за пределы игровой доски. «Не уверен, что идеи, лежащие в основе AlphaZero, будет так легко обобщить», — говорит Педро Домингос, специалист по информатике из Вашингтонского университета. «Игры – это очень, очень необычная тема».
Идеальные цели для неидеального мира
Одна общая у многих игр характеристика, включая шахматы и го – игрокам постоянно видны все фишки с обеих сторон доски. У каждого игрока есть, что называется, «идеальная информация» о состоянии игры. Какой бы сложной ни была игра, вам нужно просто думать над текущей позицией.Многие ситуации реального мира с этим не сравнить. Представьте, что мы просим компьютер поставить диагноз или провести бизнес-переговоры. «Большая часть стратегических взаимодействий в реальном мире связана со скрытой информацией», — говорит Ноам Браун, аспирант по информатике из Университета Карнеги-Мэлон. «Мне кажется, что большая часть ИИ-сообщества этот факт игнорирует».
Покер, на котором специализируется Браун, предлагает иную задачу. Вы не видите карт оппонента. Но и здесь машины, обучающиеся через игру с самими собой, уже достигают сверхчеловеческих высот. В январе 2017 года программа Libratus, созданная Брауном и его куратором Томасом Сэндхолмом, обыграла четырёх профессиональных игроков в безлимитный техасский холдем, выиграв $1,7 млн в конце 20-дневного чемпионата.
Ещё более обескураживающая игра с неидеальной информацией — StarCraft II, ещё одна многопользовательская онлайн-игра с огромным числом фанатов. Игроки выбирают команду, строят армию и ведут войну на научно-фантастическом ландшафте. Но ландшафт окружён туманом войны, из-за которого игроки видят только те части территории, на которых расположены их собственные войска или строения. Даже в решении исследовать территорию соперника полно неопределённости.
Это единственная игра, в которую ИИ пока не может выиграть. Препятствиями служат огромное количество вариантов ходов в игре, которое обычно переваливает за тысячу, и скорость принятия решений. Каждому игроку – человеку или машине – приходится беспокоиться об огромном количестве вероятных сценариев развития с каждым щелчком мышки.
Пока что соперничать на равных с людьми в этой области ИИ не может. Но это является целью для развития ИИ. В августе 2017 DeepMind скооперировалась с Blizzard Entertainment, компанией, создавшей StarCraft II, чтобы создать инструменты, которые, по их словам, откроют эту игру для исследователей ИИ.
Несмотря на всю сложность, цель StarCraft II сформулировать просто: уничтожить врага. Это роднит её с шахматами, го, покером, Dota 2 и практически любой другой игрой. В играх можно победить.
С точки зрения алгоритма у задач должна быть «целевая функция», цель, к которой надо стремиться. Когда AlphaZero играли в шахматы, это было несложно. Поражение оценивалось в -1, ничья в 0, победа в +1. Целевая функция AlphaZero – максимизация очков. Целевая функция покерного бота настолько же проста: выиграть кучу денег.
 Компьютерные ходоки могут тренировать сложное поведение, вроде ходьбы по незнакомой местности
Компьютерные ходоки могут тренировать сложное поведение, вроде ходьбы по незнакомой местности
Ситуации в реальной жизни бывают не такими простыми. К примеру, робомобилю требуется более тонкое формирование целевой функции – что-то похожее на аккуратный подбор слов при описании вашего желания джинну. К примеру: быстро доставить пассажира по правильному адресу, подчиняясь всем законам и соответствующим образом взвешивая стоимость человеческой жизни в опасных и неопределённых ситуациях. Домингос говорит, что формирование исследователями целевой функции, это «одна из тех вещей, что отличают великого исследователя в области машинного обучения от середнячка».
Рассмотрим Tay, чат-бота для Twitter, который Microsoft выпустила 23 марта 2016 года. Его целевой функцией было вовлекать людей в разговор, чем он и занимался. «Что, к сожалению, обнаружил Tay, — сказал Домингос, — так это то, что наилучшим способом максимизации вовлечения людей будет выдавать расистские оскорбления». Его отключили всего через день после начала работы.
Ваш собственный главный враг
Некоторые вещи не меняются. Используемые сегодня преобладающими игровыми ботами стратегии были придуманы много десятилетий назад. «Это такой взрыв из прошлого – ему просто дают больше вычислительных мощностей», — говорит Дэвид Дувено, специалист по информатике из Токийского университета.Стратегии часто основываются на обучении с подкреплением, техники с предоставлением свободы действия. Вместо того, чтобы заниматься микроменеджментом, настраивая мельчайшие подробности работы алгоритма, инженеры дают машине изучать окружении обучаться достижению целей самостоятельно, методом проб и ошибок. До выхода AlphaGo и его наследников, команда DeepMind достигла первого большого успеха, попавшего в заголовки, в 2013 году, когда использовала обучение с подкреплением для создания бота, научившегося играть в семь игр Atari 2600, причём в три из них – на уровне эксперта.
Этот прогресс продолжился. 5 февраля DeepMind выпустила IMPALA – ИИ-систему, способную научиться 57 играм с Atari 2600 и ещё 30 уровням, сделанным DeepMind в трёх измерениях. На них игрок действует в различных окружениях и достигает целей вроде открытия дверей или сбора грибов. IMPALA, казалось, передавала знания между заданиями – время, потраченное на одну игру, улучшало результаты в остальных.
Но в более широкой категории обучения с подкреплением, настольных и мультипользовательских играх, можно использовать более конкретный подход. Их изучение может идти в виде игры с самим собой, когда алгоритм достигает стратегического превосходства, многократно соревнуясь с близкой копией себя.
Этой идее много десятков лет. В 1950-х инженер IBM Артур Сэмюель создал программу для игры в шашки, которая частично училась играть, соревнуясь сама с собой. В 1990-х Джеральд Тезауро из IBM создал программу для игры в нарды, противопоставлявшую алгоритм самому себе. Программа дошла до уровня людей-экспертов, параллельно выдумав необычные, но эффективные стратегии игры.
Во всё возрастающем числе игр алгоритмам для игры с самим собой предоставляют равного противника. Это означает, что изменение стратегии игры приводит к иному результату, благодаря чему алгоритм получает мгновенную обратную связь. «Каждый раз, когда вы что-то узнаёте, когда открываете какую-то мелочь, ваш оппонент сразу начинает использовать её против вас», — говорит Илья Суцкевер, директор по исследованиям в OpenAI, некоммерческой организации, которую он основал вместе с Илоном Маском, посвящённой разработке и распространению ИИ-технологий и направлению их развития в безопасное русло. В августе 2017 года организация выпустила бота для Dota 2, управлявшего одним из персонажей игры, Shadow Fiend – демоном-некромантом – победившего лучших игроков мира в сражениях один на один. Ещё один проект OpenAI сталкивает симуляции людей в матче сумо, в результате чего они обучаются борьбе и уловкам. Во время игры с самим собой «некогда отдыхать, нужно постоянно совершенствоваться», — сказал Суцкевер.
OpenAI
Но старая идея игры с самим собой – только один ингредиент в преобладающих сегодня ботах, им ещё нужен способ превращения игрового опыта в более глубокое понимание предмета. В шахматах, го, видеоиграх типа Dota 2 перестановок больше, чем атомов во Вселенной. Даже если мы будем ждать несколько человеческих жизней, пока ИИ будет бороться со своей тенью на виртуальных аренах, машина не сможет реализовать каждый сценарий, записать его в специальной таблице и обращаться к ней, когда такая ситуация попадётся вновь.Чтобы оставаться на плаву в этом море возможностей, «необходимо обобщать и выделять суть», — говорит Питер Аббиль, специалист по информатике из Калифорнийского университета в Беркли. Deep Blue от IBM делала это при помощи встроенной формулы для игры в шахматы. Вооружённая возможностью оценивать силу игровых позиций, которые она ещё не видела, программа смогла применить ходы и стратегии, увеличивающие её шансы на выигрыш. В последние годы новая техника даёт возможность вообще отказаться от такой формулы. «Теперь, внезапно, всё это охватывает „глубинная сеть“, — сказал Аббиль.
Глубинные нейросети, популярность которых взлетела в последние годы, строятся из слоёв искусственных „нейронов“, наслоённых друг на друга, будто стопка блинов. Когда нейрон в одном из слоёв активируется, он отправляет сигналы на уровень выше, а там их отправляют ещё выше, и так далее.
Подстраивая связи между уровнями, эти сети удивительно справляются с превращением входных данных в связанные с ними выходные, даже если связь между ними кажется абстрактной. Дайте им фразу на английском, и они смогут натренироваться, переводя её на турецкий. Дайте им изображения приютов для животных, и они смогут определить, какой из них для кошек. Покажите им игровое поли, и они смогут понять вероятность выигрыша. Но обычно таким сетям сначала необходимо предоставить списки из помеченных примеров, на которых они смогут практиковаться.
Именно поэтому игра с самим собой и глубинные нейросети так хорошо сочетаются друг с другом. Самостоятельные игры выдают огромное количество сценариев, и у глубинной сети оказывается практически неограниченное количество данных для тренировки. А потом нейросеть предлагает способ усвоить опыт и закономерности, встреченные во время игры.
Но есть подвох. Чтобы такие системы выдавали полезные данные, им нужна реалистичная площадка для игр.
»Все эти игры, все эти результаты, достигались в условиях, позволявших идеально симулировать мир", — говорит Челси Финн, аспирант из Беркли, использующая ИИ для управления роботизированными руками и интерпретации данных, полученных с датчиков. Другие области не так легко имитировать.
Робомобили, к примеру, с трудом справляются с плохой погодой или с велосипедистами. Или они могут не воспринять необычные возможности, встречающиеся в реальном мире – типа птицы, летящей прямо в камеру. В случае с роботизированными руками, как говорит Финн, начальные симуляции давали базовую физику, позволявшую руке выучиться тому, как учиться. Но они не справляются с деталями прикосновений к разным поверхностям, поэтому задачи типа закручивания крышки бутылки – или проведения сложной хирургической операции – требуют опыта, полученного в реальности.
В случае проблем, которые сложно симулировать, игры с самим собой уже не будут такими полезными. «Существует большая разница между по-настоящему идеальной моделью окружения, и выученной примерной моделью, особенно когда реальность по-настоящему сложна», — написал мне Йошуа Бенджио, пионер глубинного обучения из Монреальского университета. Но у исследователей ИИ всё равно остаются способы двигаться дальше.
Жизнь после игр
Сложно точно указать начало превосходства ИИ в играх. Можно выбрать проигрыш Каспарова в шахматах, поражение Ли Седоля от виртуальных рук AlphaGo. Другим популярным вариантом будет тот день 2011 года, когда легендарный чемпион игры Jeopardy! Кен Дженнингс проиграл IBM Watson. Watson был способен обрабатывать подсказки и игру слов. «Я приветствую появление наших новых компьютерных повелителей», — написал Дженнингс под своим последним ответом.Создавалось впечатление, что у Watson есть офисные навыки подобные тем, что люди используют для решения множества реальных задач. Он мог воспринять ввод на английском языке, обработать связанные с ним документы в мгновение ока, выудить связные кусочки информации и выбрать один наилучший ответ. Но спустя семь лет реальность продолжает ставить сложные препятствия перед ИИ. В сентябрьском отчёте по здравоохранению агентства Stat указано, что наследник Watson, специализирующийся на исследованиях раковых заболеваний и выработке персонифицированных рекомендаций для лечения Watson for Oncology, столкнулся с проблемами.
«Вопросы в игре Jeopardy! Проще обрабатывать, поскольку для этого не требуется здравый смысл», — писал Бенджио, работавший совместно с командой Watson, в ответ на просьбу сравнить два этих случая с точки зрения ИИ. «Понять медицинскую статью гораздо сложнее. Требуется провести большой объём базовых исследований».
Но пусть игры и узко специализированы, они напоминают несколько реальных задач. Исследователи из DeepMind не захотели отвечать на вопросы интервью, указав, что их работу по AlphaZero в данный момент изучают независимые специалисты. Но команда предположила, что такая технология вскоре сможет помочь исследователям биомедицины, желающим разобраться в свёртывании белков.
Для этого им необходимо разобраться с тем, как различные аминокислоты, составляющие белок, гнутся и сворачиваются в небольшую трёхмерную машину, функциональность которой зависит от её формы. Эта сложность похожа на сложность шахмат: химикам известны законы на таком уровне, чтобы достаточно грубо обсчитывать определённые сценарии, но возможных конфигураций существует столько, что провести поиск по всем возможным вариантам не получится. Но что, если сворачивание белков можно представить в виде игры? А это уже предпринимали. С 2008 года сотни тысяч людей попробовали онлайн-игру Foldit, в которой пользователям начисляются очки за стабильность и реальность свёрнутой ими белковой структуры. Машина могла бы тренироваться сходным образом, возможно, пытаясь превзойти своё предыдущее лучшее достижение при помощи обучения с подкреплением.
Обучение с подкреплением и игра с самим собой могут помочь тренировать и диалоговые системы, предполагает Сацкевер. Это может дать роботам, которые должны беседовать с людьми, шанс натренироваться в этом, разговаривая с самим собой. Учитывая, что специализированное оборудование для работы ИИ становится быстрее и доступнее, у инженеров появляется всё больше стимулов к оформлению задач в виде игр. «Думаю, что в будущем важность игры с самим собой и других способов потребления большого количества вычислительных мощностей будет возрастать», — сказал Сацкевер.
Но если итоговой целью машин ставить повторение всего, на что способен человек, то даже обобщённому чемпиону по игре в настольные игры вроде AlphaZero ещё есть, куда расти. «Необходимо обратить внимание, по крайней мере, мне это очевидно, на огромную пропасть между реальным мышлением, творческим исследованием идей и сегодняшними способностями ИИ», — говорит Джон Тененбаум, когнитивист из MTI. «Такой интеллект существует, но пока только в умах великих исследователей ИИ».
Многие другие исследователи, ощущающие шумиху вокруг их области, предлагают собственные критерии. «Я бы порекомендовал не переоценивать важность этих игр, для ИИ или для задач общего назначения. Люди не очень хорошо умеют играть в игру, — говорит Франсуа Шоле, исследователь глубинного обучения в Google. – Но имейте в виду, что с помощью даже очень простых и специализированных инструментов можно достичь многого».
habr.com
Google создала полностью самообучаемый искусственный интеллект
DeepMind — ИИ-подразделение Google, базирующееся в Лондоне, — разработало улучшенную версию программы AlphaGo, которая прославилась победой над чемпионом по игре в го Ли Седолем в прошлом году. Инженеры переписали алгоритмы нейросети, сделав её полностью самообучаемой: AlphaGo Zero способна "тренироваться" сама, без какого-либо участия со стороны человека.
На то, чтобы освоить правила игры в го — древнюю настольную стратегию, которая возникла в Китае свыше 2 тысяч лет назад, — искусственному интеллекту потребовалось всего несколько часов. Уже через три дня новая нейросеть превзошла AlphaGo Lee — версию, которая одолела профессионального игрока из Южной Кореи со счетом 4:1 в 2016 году.
Через 21 день разработка DeepMind приблизилась к уровню AlphaGo Master — онлайн-версии, которая в 2017-м победила топ-60 сильнейших игроков в го, включая чемпиона мира Ки Джи во всех 3-х партиях. А 40 дней спустя AlphaGo Zero обыграла все свои ранние инкарнации, став самым совершенным алгоритмом. Когда новому ИИ дали сразиться с версией AlphaGo 2016 года, его противник был разгромлен со счетом 100:0.
Если AlphaGo Lee училась на ходах профессионалов, то "самоучка" Google на начальном этапе располагала только самыми базовыми правилами игры, пишет The Guardian. Она играла сама с собой миллионы раз: перед каждым ходом алгоритмы анализировали позиции фигур на доске и вычисляли оптимальное решение, которое с самой большой вероятностью может привести к победе. После игры нейросеть обновлялась, чтобы в следующей партии сразиться с более сильной версией себя.
Го долгое время считалась слишком сложной стратегией для компьютеров. В отличие от шахмат, она требует интуитивного мышления и тактики, подразумевает огромное количество возможных ходов и комбинаций. Это сильно усложняет создание алгоритмов для их анализа и предсказаний действий соперника.
Поделитесь новостью:
hitech.vesti.ru
Программы искусственного интеллекта для общения с виртуальным собеседником
Искусственный интеллект (ИИ) – это система алгоритмов имитирующая интеллектуальную деятельность человека.
Алгоритмы принятия решений основаны на элементарной логике и в зависимости от возможностей системы ИИ могут решать задачи разного уровня сложности.
Моделирование разумного поведения системой ИИ проявляется в принятии логических решений на базе готовых способов их решения.
Структура системы ИИ включает в себя три основных блока – информационную базу, блок принятия решений и интерфейс, позволяющий вести общение в удобной для пользователя форме.
Самообучающиеся программы ИИ на начальном этапе действуют по принципу «делай как я», повторяя алгоритмы действий пользователя, а в дальнейшем могут использовать более сложные комбинации для принятия решений.
Самообучение системы ИИ в процессе работы, основанное на расширении информационной базы и алгоритмов решения задач является непосредственным признаком квазиразумного поведения или искусственного интеллекта.
В идеале искусственный интеллект - это имитация действующей модели мышления человека выраженная в цифровой форме.
Представленные ниже программы общения предназначены для ведения контекстно-зависимого диалога пользователя и системы ИИ.
В процессе общения пополняется багаж знаний программы, запоминаются варианты ответов на поставленные вопросы.При должной прокачке можно развить уровень интеллекта диалоговой программы ИИ до вполне приемлемого уровня общения.
Программы ИИ для общения с виртуальным собеседником
Помимо локальных программ общения, можно воспользоваться онлайн сервисом виртуальных собеседников для диалогового общения А-я-яй.ру
А-я-яй.ру – бесплатный сервис по созданию, обучению и демонстрации другим пользователям инфов – виртуальных существ, с которыми можно поддерживать диалог посредством текстового чата.
Поговорите с этим роботом, только не учите его плохому - он еще совсем маленький! ))
Уверен, что через некоторое время он сможет строить более интересные диалоги!
На сервисе А-я-яй.ру можно создать персонального виртуального собеседника для диалогового общения. Его персонажи могут быть использованы для общения с пользователями в блогах и социальных сетях.
"Говорящие" приложения под Андроид лучше поискать на https://play.google.com
Скачать и установить бесплатную программу искусственного интеллекта для общения на Андроид можно здесь: Чатбот roBot
virtualizacia.net
Как создать искусственный интеллект? | GeekBrains
Что надо знать и с чего начать.
На этой неделе вы могли прочитать крайне мотивирующей кейс от Валерия Турова, где он рассказал об одной из своих целей, которая привела в профессию – желанию познать принцип работы и научиться создавать самому игровых ботов.
А ведь действительно, именно желание создать совершенный искусственный интеллект, будь то игровая модель или мобильная программа, сподвигла на путь программиста многих из нас. Проблема в том, что за тоннами учебного материала и суровой действительностью заказчиков, это самое желание было заменено простым стремлением к саморазвитию. Для тех, кто так и не приступил к исполнению детской мечты, далее краткий путеводитель по созданию настоящего искусственного разума.

Стадия 1. Разочарование
Когда мы говорим о создании хотя бы простых ботов, глаза наполняются блеском, а в голове мелькают сотни идей, что он должен уметь делать. Однако, когда дело доходит до реализации, оказывается, что ключом к разгадке реальной модели поведения является...математика. Если быть немного конкретнее, то вот список её разделов, которые необходимо проштудировать хотя бы в формате университетского образования:
-
Линейная алгебра;
-
Логика;
-
Теория графов;
-
Теория вероятностей и математическая статистика.
Этот тот научный плацдарм, на котором будут строится ваше дальнейшее программирование. Без знания и понимания этой теории все задумки быстро разобьются о взаимодействие с человеком, ведь искусственный разум на самом деле не больше, чем набор формул.
Стадия 2. Принятие
Когда спесь немного сбита студенческой литературой, можно приступать к изучению языков. Бросаться на LISP или другие функциональные языки пока не стоит, для начала надо научиться работать с переменными и однозначными состояниями. Как для быстрого изучения, так и дальнейшего развития прекрасно подойдёт Python, но в целом можно взять за основу любой язык, имеющий соответствующие библиотеки.
Стадия 3. Развитие
Теперь переходим непосредственно к теории ИИ. Их условно можно разделить на 3 категории:
-
Слабый ИИ – боты, которых мы видим в компьютерных играх, или простые подручные помощники, вроде Siri. Они или выполняют узкоспециализированные задачи или являются незначительным комплексом таковых, а любая непредсказуемость взаимодействия ставит их в тупик.
-
Сильный ИИ – это машины, интеллект которых сопоставим с человеческим мозгом. На сегодняшний день нет реальных представителей этого класса, но компьютеры, вроде Watson очень близки к достижению этой цели.
-
Совершенные ИИ – будущее, машинный мозг, который превзойдёт наши возможности. Именно об опасности таких разработок предупреждают Стивен Хоккинг, Элон Маск и кинофраншиза «Терминатор».
Естественно, начинать следует с самых простых ботов. Для этого вспомните старую-добрую игру «Крестики-нолики» при использовании поля 3х3 и постарайтесь выяснить для себя основные алгоритмы действий: вероятность победы при безошибочных действиях, наиболее удачные места на поле для расположения фигуры, необходимость сводить игру к ничьей и так далее.
Сыграв несколько десятков партий и анализируя собственные действия, вы наверняка сможете выделить все важные аспекты и переписать их в машинный код. Если нет, то продолжайте думать, а эта ссылка здесь полежит на всякий случай.
К слову, если вы всё-таки взялись за язык Python, то создать довольно простого бота можно обратившись к этому подробному мануалу. Для других языков, таких как C++ или Java, вам также не составит труда найти пошаговые материалы. Почувствовав, что за созданием ИИ нет ничего сверхъестественного, вы сможете смело закрыть браузер и приступить к личным экспериментам.
Стадия 4. Азарт
Теперь, когда дело сдвинулось с мёртвой точки, вам наверняка хочется создать что-то более серьёзное. В этом вам поможет ряд следующих ресурсов:
Как вы поняли даже из названий, это API, которые позволят без лишних затрат времени создать некоторое подобие серьёзного ИИ.

Стадия 5. Работа
Теперь же, когда вы уже вполне ясно представляете, как ИИ создавать и чем при этом пользоваться, пора выводить свои знания на новый уровень. Во-первых, для этого потребуется изучение дисциплины, которое носит название «Машинное обучение». Во-вторых, необходимо научиться работать с соответствующими библиотеками выбранного языка программирования. Для рассматриваемого нами Python это Scikit-learn, NLTK, SciPy, PyBrain и Nump. В-третьих, в развитии никуда не обойтись от функционального программирования. Ну и самое главное, вы теперь сможете читать литературу о ИИ с полным пониманием дела:
-
Artificial Intelligence for Games, Ян Миллингтон;
-
Game Programming Patterns, Роберт Найсторм;
-
AI Algorithms, Data Structures, and Idioms in Prolog, Lisp, and Java, Джордж Люгер, Уильям Стбалфилд;
-
Computational Cognitive Neuroscience, Рэнделл О’Рейли, Юко Мунаката;
-
Artificial Intelligence: A Modern Approach, Стюарт Рассел, Питер Норвиг.
И да, вся или почти вся литература по данной тематике представлена на иностранном языке, поэтому если хотите заниматься созданием ИИ профессионально необходимо подтянуть свой английский до технического уровня. Если вы только начинаете путь к мечте, советуем записаться на бесплатный двухчасовой интенсив по основам программирования.
В остальном, ваше дальнейшее развитие будет зависеть лишь от практики и желания усложнять алгоритмы. Но будьте осторожны: возможно совершенный искусственный разум опасен для человечества?
geekbrains.ru
- Книги для академии fable 3

- Игра скайрим карты
- Настоящий бэтмен

- Транспорт starbound

- Класс игры

- Бранн игра престолов

- Operation 7

- Краш тест ворлд оф танкс

- Лучшие игры без интернета андроид

- Дарк соулс 3 что означают буквы a b c s d

- Metal gear solid v the phantom pain как определить зараженных на базе
